From TF to EVB - testing, profiling, and deploying AI models
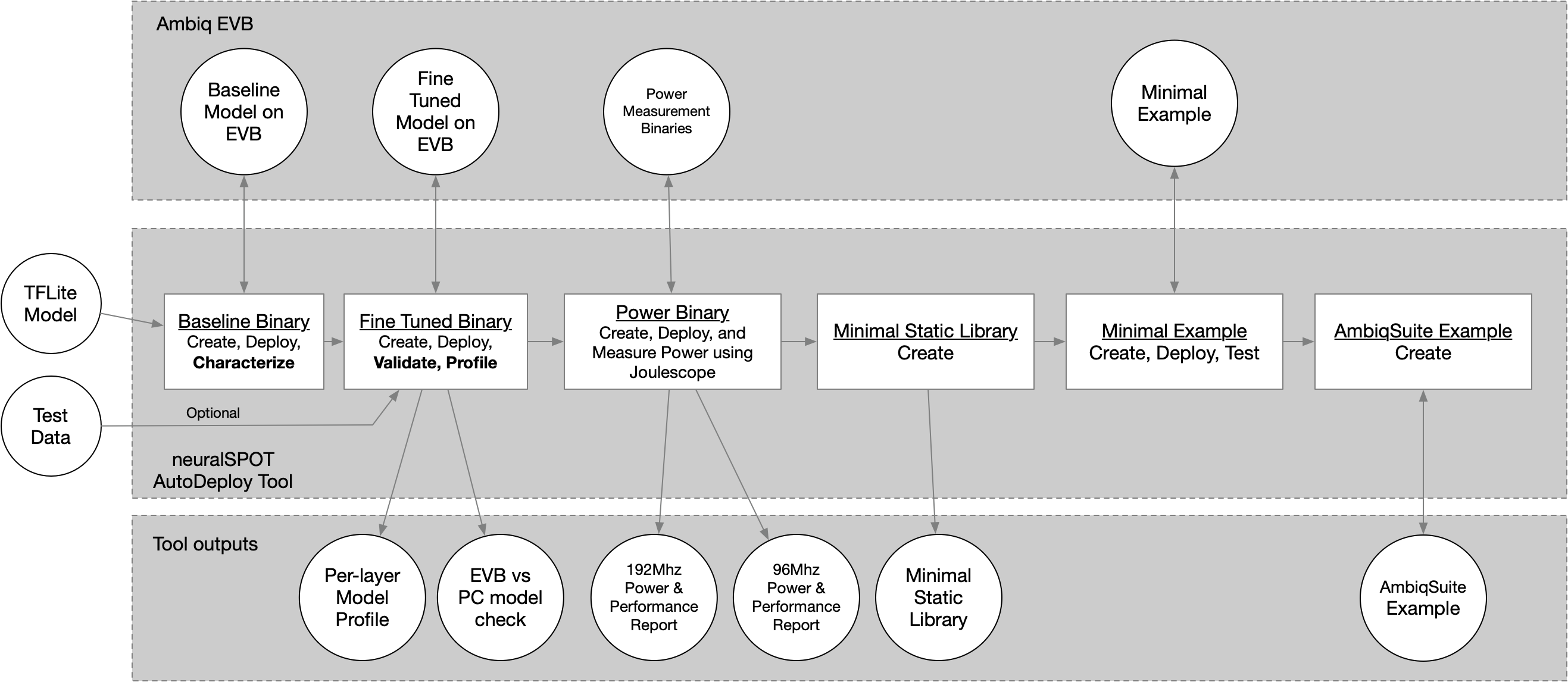
Autodeploy automates the creation, deployment, validation, and profiling of TFlite models on Ambiq EVBs
Developing AI models is hard. Deploying them on embedded devices is also hard. Developing AI features for embedded devices requires doing both of these hard things over and over again until everything is working and optimized. By automating the model conversion, deployment, and characterization process, Ambiq's neuralSPOT Autodeploy tool can help accelerate this cycle.
The Old Way of Doing Things
Developing an AI feature typically involves a repetitive process:
- An AI developer produces a model that implements the feature more or less optimally
- That model is converted to code that can execute on an EVB. This is a complex process that requires manually generating new code every time the model changes.
- That code is deployed and tested on the EVB. Problems may arise from numeric mismatches, memory issues, and performance (latency) issues.
- The AI developer analyses and debugs any issues, tweaks the model in an attempt to mitigate them, and jumps back to step 1.
Each of of these steps is mostly manual, complex, and fraught with the potential for coding errors.
Fortunately, all the information needed to automate the middle 2 steps is tucked in Tensorflow's representation of the model - all that is needed is a convenient way to extract it, and an automation flow that takes advantage of that info.
Ambiq's AutoDeploy is Here to Help
AutoDeploy is a tool that speeds up the AI/Embedded iteration cycle by automating most of the tedious bits - given a TFLite file, the tool will convert it to code that can run on an Ambiq EVB, then run a series of tests to characterize its embedded behavior. It then generates a minimal static library suitable implementing the model for easy integration into applications.
Pain Points
AutoDeploy was designed to address many common pain points:
- Code Generation Pain
- Automatically figures out the right Tensor Arena, Resource Variable Arena, and Profile Data sizes
- Produces a minimal TFLite for Microcontroller instance by determining which Ops are actually needed and only including those
- Model Behavior Mismatches
- AutoDeploy runs the same model inputs on the PC and EVB, and compares the results, leading to early discovery and easier debugging of behavior differences. Configuration of the model, input/output tensors, and statistics gathering are driven by AutoDeploy using RPC.
- Model Performance Profiling
- AutoDeploy extends the TFLite for Microcontrollers Profiling to produce detailed reports including per-layer latency, MAC count, and cache and CPU performance statistics.
- Model Power Usage Profiling
- If a Joulescope is available, AutoDeploy can use it to automatically measure the model inference power consumption.
Using AutoDeploy
Getting the Hardware Ready
Autodeploy uses RPC-over-USB or RPC-over-UART to communicate with the device. Optionally, it can use a joulescope to automatically measure power - this requires GPIO connections between the EB/EVB and the Joulescope.
| Development Platform | Transport | USB Connections |
|---|---|---|
| Apollo3P, Apollo4 Lite (include BLE variants) | UART | 1 (the Jlink connection) |
| Apollo4P | USB or UART | 2 (one for Jlink, on for USB) |
| Apollo510 (with J17 selecting Jlink, which is the default) | USB or UART | 2 (one for Jlink, one for USB) |
| Apollo510 (with J17 selecting AP5) | USB or UART | 1 (the one labeled USB_AP%) |
The RPC transport mode is selected using the --transport command line parameter.
Installing and Running Autodeploy
Autodeploy can be installed via pip:
cd neuralSPOT
pip install .
Using AutoDeploy is easy - just give it a TFLite model, connect an EVB, and let it go to work:
$> ns_autodeploy --tflite-filename=mymodel.tflite --model-name mymodel --measure-power
As part of the process, AutoDeploy generates a number of artifacts, including three ready-to-deploy binary files and the source code used to generate them:
.../projects/autodeploy
./mymodel
./mymodel
./lib # minimal static library and API header
./src # tiny example that compiles the lib into an EVB image
./mymodel_ambiqsuite_example
./gcc # Makefile and linking scripts for GCC
./armclang # Makefile and linking scripts for armclang
./make # helper makefiles
./src # The model and a small example app that calls it once
./tensorflow_headers # minimal needed to invoke TFLM
./tflm_validator
./src # Highly instrumented model validation application (leverages USB and RPC)
./mymodel_power
./src # Power measurement application (requires Joulescope and GPIO connections)
mymodel.csv # Per-layer profile
mymodel_mc.pkl # artifact generated during validation, useful for non-USB EVBs
mymodel_md.pkl # artifact generated during validation, useful for non-USB EVBs
mymodel.csv file contains a CSV representation of per-layer profiling stats. For a a Keyword Spotting model running on Apollo4 Plus, for example, the CSV contains the following:
| Event | Tag | uSeconds | Est MACs | cycles | cpi | exc | sleep | lsu | fold | daccess | dtaglookup | dhitslookup | dhitsline | iaccess | itaglookup | ihitslookup | ihitsline |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | CONV_2D | 47794 | 320000 | 9176380 | 141 | 252 | 0 | 188 | 166 | 58335 | 55777 | 0 | 2558 | 1220789 | 357761 | 0 | 863028 |
| 1 | DEPTHWISE_C | 23334 | 72000 | 4480072 | 153 | 54 | 0 | 200 | 123 | 30068 | 25311 | 0 | 4757 | 625707 | 175380 | 0 | 450327 |
| 2 | CONV_2D | 44674 | 512000 | 8577368 | 168 | 102 | 0 | 96 | 194 | 81745 | 80093 | 0 | 1652 | 1087045 | 309917 | 0 | 777128 |
| 3 | DEPTHWISE_C | 23337 | 72000 | 4480468 | 74 | 147 | 0 | 77 | 126 | 30072 | 25311 | 0 | 4761 | 625704 | 175399 | 0 | 450305 |
| 4 | CONV_2D | 44671 | 512000 | 8578178 | 1 | 120 | 0 | 21 | 195 | 81736 | 80070 | 0 | 1666 | 1086915 | 309928 | 0 | 776987 |
| 5 | DEPTHWISE_C | 23328 | 72000 | 4478896 | 44 | 99 | 0 | 225 | 122 | 30059 | 25301 | 0 | 4758 | 625584 | 175343 | 0 | 450241 |
| 6 | CONV_2D | 44676 | 512000 | 8576362 | 83 | 135 | 0 | 27 | 195 | 81736 | 80079 | 0 | 1657 | 1086955 | 309892 | 0 | 777063 |
| 7 | DEPTHWISE_C | 23336 | 72000 | 4478996 | 85 | 238 | 0 | 165 | 118 | 30067 | 25313 | 0 | 4754 | 625660 | 175393 | 0 | 450267 |
| 8 | CONV_2D | 44675 | 512000 | 8577472 | 118 | 184 | 0 | 161 | 196 | 81745 | 80092 | 0 | 1653 | 1087073 | 309922 | 0 | 777151 |
| 9 | AVERAGE_POO | 583 | 0 | 111772 | 100 | 169 | 0 | 39 | 197 | 202 | 177 | 0 | 25 | 60827 | 1541 | 0 | 59286 |
| 10 | RESHAPE | 21 | 0 | 3748 | 213 | 74 | 0 | 219 | 1 | 31 | 24 | 0 | 7 | 422 | 142 | 0 | 280 |
| 11 | FULLY_CONNE | 134 | 768 | 25644 | 69 | 76 | 0 | 249 | 21 | 275 | 263 | 0 | 12 | 3014 | 911 | 0 | 2103 |
| 12 | SOFTMAX | 85 | 0 | 17574 | 227 | 231 | 0 | 24 | 43 | 102 | 63 | 0 | 39 | 2552 | 717 | 0 | 1835 |
This information is collected from a number of sources based on both static analysis on the PC and dynamic profiling on the EVB: Dynamically collected statistics are:
- The Tag and uSeconds come from TFLM's micro-profiler and is collected by TFLM during the first inference only
- The cycles, cpi, exc, sleep, lsu, and fold come from Arm's ETM profiling registers and are measured during the first inference only
- The daccess, dtaglookup, dhitslook, dhitsline, iaccess, itagelookup, ihitslookup, and ihitsline come from Ambiq cache profiling module and are measured during the first inference only
Estimated MACs are based on a static analysis of the TFLite file and are calculated as the theoretical MAC per layer type and shape.
Apollo510 PMU Event Collection
Apollo510 has a rich set of performance monitoring registers (the Performance Measurement Unit). Only four of these 70+ counters can be enabled at once, but Autodeploy has a mode where all counters can be collected on a per-layer basis.
Autodeploy collects this data in one of two ways:
- Collect only 4 counters. Which events are collected can be defined via a yaml file such as NS_PMU_CACHES.yaml.
- Collect all the counters. This is accomplished by running the model repeatedly, collected a different set of counters each time. Importantly, this assumes the model performance doesn't vary significantly across each run - empirically, this assumption holds up. To enable this mode, specify the --full-pmu-capture command line argument.
When full PMU capture is enabled, the CSV contains a rich set of data, some of which is derived from a static analysis of the model (e.g. filter shapes, estimated loads and stores, etc). For example, the same model as above (KWS) running on Apollo510 with --full-pmu-capture produces the following CSV:
| Event | Tag | uSeconds | EST_MAC | MAC_EQ | OUTPUT_MAG | OUTPUT_SHAPE | FILTER_SHAPE | STRIDE_H | STRIDE_W | DILATION_H | DILATION_W | ARM_PMU_SW_INCR | ARM_PMU_L1I_CACHE_REFILL | ARM_PMU_L1D_CACHE_REFILL | ARM_PMU_L1D_CACHE | ARM_PMU_LD_RETIRED | ARM_PMU_ST_RETIRED | ARM_PMU_INST_RETIRED | ARM_PMU_EXC_TAKEN | ARM_PMU_EXC_RETURN | ARM_PMU_PC_WRITE_RETIRED | ARM_PMU_BR_IMMED_RETIRED | ARM_PMU_BR_RETURN_RETIRED | ARM_PMU_UNALIGNED_LDST_RETIRED | ARM_PMU_CPU_CYCLES | ARM_PMU_MEM_ACCESS | ARM_PMU_L1I_CACHE | ARM_PMU_L1D_CACHE_WB | ARM_PMU_BUS_ACCESS | ARM_PMU_MEMORY_ERROR | ARM_PMU_BUS_CYCLES | ARM_PMU_CHAIN | ARM_PMU_L1D_CACHE_ALLOCATE | ARM_PMU_BR_RETIRED | ARM_PMU_BR_MIS_PRED_RETIRED | ARM_PMU_STALL_FRONTEND | ARM_PMU_STALL_BACKEND | ARM_PMU_LL_CACHE_RD | ARM_PMU_LL_CACHE_MISS_RD | ARM_PMU_L1D_CACHE_MISS_RD | ARM_PMU_STALL | ARM_PMU_L1D_CACHE_RD | ARM_PMU_LE_RETIRED | ARM_PMU_LE_CANCEL | ARM_PMU_SE_CALL_S | ARM_PMU_SE_CALL_NS | ARM_PMU_MVE_INST_RETIRED | ARM_PMU_MVE_FP_RETIRED | ARM_PMU_MVE_FP_HP_RETIRED | ARM_PMU_MVE_FP_SP_RETIRED | ARM_PMU_MVE_FP_MAC_RETIRED | ARM_PMU_MVE_INT_RETIRED | ARM_PMU_MVE_INT_MAC_RETIRED | ARM_PMU_MVE_LDST_RETIRED | ARM_PMU_MVE_LD_RETIRED | ARM_PMU_MVE_ST_RETIRED | ARM_PMU_MVE_LDST_CONTIG_RETIRED | ARM_PMU_MVE_LD_CONTIG_RETIRED | ARM_PMU_MVE_ST_CONTIG_RETIRED | ARM_PMU_MVE_LDST_NONCONTIG_RETIRED | ARM_PMU_MVE_LD_NONCONTIG_RETIRED | ARM_PMU_MVE_ST_NONCONTIG_RETIRED | ARM_PMU_MVE_LDST_MULTI_RETIRED | ARM_PMU_MVE_LD_MULTI_RETIRED | ARM_PMU_MVE_ST_MULTI_RETIRED | ARM_PMU_MVE_LDST_UNALIGNED_RETIRED | ARM_PMU_MVE_LD_UNALIGNED_RETIRED | ARM_PMU_MVE_ST_UNALIGNED_RETIRED | ARM_PMU_MVE_LDST_UNALIGNED_NONCONTIG_RETIRED | ARM_PMU_MVE_VREDUCE_RETIRED | ARM_PMU_MVE_VREDUCE_FP_RETIRED | ARM_PMU_MVE_VREDUCE_INT_RETIRED | ARM_PMU_MVE_PRED | ARM_PMU_MVE_STALL | ARM_PMU_MVE_STALL_RESOURCE | ARM_PMU_MVE_STALL_RESOURCE_MEM | ARM_PMU_MVE_STALL_RESOURCE_FP | ARM_PMU_MVE_STALL_RESOURCE_INT | ARM_PMU_MVE_STALL_BREAK | ARM_PMU_MVE_STALL_DEPENDENCY | ARM_PMU_ITCM_ACCESS | ARM_PMU_DTCM_ACCESS |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | CONV_2D | 1559 | 320000 | 10425564*1 | 8000 | 1255*64 | 64104*1 | 2 | 2 | 1 | 1 | 0 | 13 | 0 | 661 | 91422 | 26654 | 299664 | 51 | 51 | 19172 | 23293 | 349 | 8074 | 385342 | 215021 | 63962 | 0 | 513 | 0 | 385353 | 0 | 513 | 0 | 385353 | 2318 | 57686 | 0 | 0 | 0 | 59838 | 641 | 2050 | 14 | 0 | 0 | 100474 | 0 | 0 | 0 | 0 | 54947 | 26000 | 45495 | 38490 | 7005 | 43511 | 38490 | 5021 | 1984 | 0 | 1984 | 0 | 0 | 0 | 8074 | 3699 | 4375 | 0 | 30144 | 0 | 30144 | 10048 | 21391 | 19391 | 7404 | 0 | 11989 | 0 | 2000 | 0 | 213720 |
| 1 | DEPTHWISE_CONV_2D | 924 | 72000 | 3325564 | 8000 | 1255*64 | 133*64 | 1 | 1 | 1 | 1 | 0 | 21 | 0 | 398 | 40789 | 11428 | 162822 | 30 | 30 | 12672 | 7085 | 227 | 2248 | 227158 | 115619 | 38209 | 0 | 307 | 0 | 227154 | 0 | 303 | 0 | 227164 | 2077 | 54469 | 0 | 0 | 0 | 56465 | 390 | 1647 | 18 | 0 | 0 | 104402 | 0 | 0 | 0 | 0 | 64368 | 20496 | 36498 | 29434 | 7064 | 36498 | 29434 | 7064 | 0 | 0 | 0 | 0 | 0 | 0 | 2248 | 0 | 2248 | 0 | 0 | 0 | 0 | 0 | 40678 | 27267 | 12781 | 0 | 14481 | 0 | 13410 | 0 | 114825 |
| 2 | CONV_2D | 968 | 512000 | 1125564*64 | 8000 | 1255*64 | 6411*64 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 420 | 71995 | 12873 | 189381 | 32 | 32 | 11133 | 2780 | 203 | 0 | 241234 | 229484 | 35017 | 0 | 323 | 0 | 241251 | 0 | 323 | 0 | 241253 | 439 | 33577 | 0 | 0 | 1 | 33910 | 412 | 2064 | 21 | 0 | 0 | 110480 | 0 | 0 | 0 | 0 | 64165 | 34000 | 46283 | 44278 | 2005 | 44299 | 44278 | 21 | 1984 | 0 | 1984 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 40192 | 0 | 40192 | 0 | 13988 | 11988 | 1 | 0 | 11985 | 0 | 2000 | 0 | 228672 |
| 3 | DEPTHWISE_CONV_2D | 911 | 72000 | 3325564 | 8000 | 1255*64 | 133*64 | 1 | 1 | 1 | 1 | 0 | 2 | 0 | 398 | 40789 | 11428 | 162815 | 30 | 31 | 12699 | 7102 | 233 | 2248 | 227691 | 115717 | 38287 | 0 | 313 | 0 | 227687 | 0 | 313 | 0 | 227673 | 2084 | 54812 | 0 | 0 | 0 | 56788 | 402 | 1649 | 15 | 0 | 0 | 104402 | 0 | 0 | 0 | 0 | 64368 | 20496 | 36498 | 29434 | 7064 | 36498 | 29434 | 7064 | 0 | 0 | 0 | 0 | 0 | 0 | 2248 | 0 | 2248 | 0 | 0 | 0 | 0 | 0 | 40674 | 27262 | 12785 | 0 | 14481 | 0 | 13412 | 0 | 114903 |
| 4 | CONV_2D | 967 | 512000 | 1125564*64 | 8000 | 1255*64 | 6411*64 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 420 | 71995 | 12873 | 189379 | 32 | 32 | 11130 | 2780 | 203 | 0 | 241297 | 229510 | 35047 | 0 | 323 | 0 | 241249 | 0 | 327 | 0 | 241277 | 440 | 33566 | 0 | 0 | 0 | 33914 | 412 | 2059 | 26 | 0 | 0 | 110480 | 0 | 0 | 0 | 0 | 64165 | 34000 | 46283 | 44278 | 2005 | 44299 | 44278 | 21 | 1984 | 0 | 1984 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 40192 | 0 | 40192 | 0 | 13987 | 11987 | 1 | 0 | 11986 | 0 | 2000 | 0 | 228664 |
| 5 | DEPTHWISE_CONV_2D | 913 | 72000 | 3325564 | 8000 | 1255*64 | 133*64 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 398 | 40789 | 11428 | 162815 | 30 | 30 | 12673 | 7085 | 227 | 2248 | 227168 | 115613 | 38208 | 0 | 303 | 0 | 227162 | 0 | 303 | 0 | 227179 | 2085 | 54471 | 0 | 0 | 0 | 56461 | 390 | 1647 | 18 | 0 | 0 | 104402 | 0 | 0 | 0 | 0 | 64368 | 20496 | 36498 | 29434 | 7064 | 36498 | 29434 | 7064 | 0 | 0 | 0 | 0 | 0 | 0 | 2248 | 0 | 2248 | 0 | 0 | 0 | 0 | 0 | 40670 | 27260 | 12782 | 0 | 14483 | 0 | 13412 | 0 | 114823 |
| 6 | CONV_2D | 968 | 512000 | 1125564*64 | 8000 | 1255*64 | 6411*64 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 420 | 71995 | 12873 | 189383 | 32 | 32 | 11133 | 2780 | 203 | 0 | 241236 | 229486 | 35024 | 0 | 323 | 0 | 241209 | 0 | 323 | 0 | 241214 | 439 | 33575 | 0 | 0 | 0 | 33918 | 412 | 2071 | 18 | 0 | 0 | 110480 | 0 | 0 | 0 | 0 | 64165 | 34000 | 46283 | 44278 | 2005 | 44299 | 44278 | 21 | 1984 | 0 | 1984 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 40192 | 0 | 40192 | 0 | 13987 | 11987 | 1 | 0 | 11984 | 0 | 2000 | 0 | 228646 |
| 7 | DEPTHWISE_CONV_2D | 911 | 72000 | 3325564 | 8000 | 1255*64 | 133*64 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 398 | 40789 | 11428 | 162815 | 30 | 30 | 12673 | 7085 | 227 | 2248 | 227165 | 115612 | 38216 | 0 | 303 | 0 | 227162 | 0 | 303 | 0 | 227139 | 2088 | 54463 | 0 | 0 | 1 | 56451 | 390 | 1646 | 21 | 0 | 0 | 104402 | 0 | 0 | 0 | 0 | 64368 | 20496 | 36498 | 29434 | 7064 | 36498 | 29434 | 7064 | 0 | 0 | 0 | 0 | 0 | 0 | 2248 | 0 | 2248 | 0 | 0 | 0 | 0 | 0 | 40677 | 27267 | 12782 | 0 | 14484 | 0 | 13415 | 0 | 114825 |
| 8 | CONV_2D | 967 | 512000 | 1125564*64 | 8000 | 1255*64 | 6411*64 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 420 | 71995 | 12873 | 189378 | 32 | 32 | 11131 | 2780 | 203 | 0 | 241321 | 229516 | 35067 | 0 | 333 | 0 | 241810 | 0 | 333 | 0 | 241761 | 439 | 33567 | 0 | 0 | 0 | 33911 | 412 | 2058 | 20 | 0 | 0 | 110480 | 0 | 0 | 0 | 0 | 64165 | 34000 | 46283 | 44278 | 2005 | 44299 | 44278 | 21 | 1984 | 0 | 1984 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 40192 | 0 | 40192 | 0 | 13986 | 11986 | 1 | 0 | 11984 | 0 | 2000 | 0 | 228673 |
| 9 | AVERAGE_POOL_2D | 66 | 0 | 0 | 64 | 111*64 | 000*0 | 0 | 0 | 0 | 0 | 0 | 27 | 0 | 54 | 772 | 155 | 8996 | 2 | 1 | 668 | 281 | 17 | 0 | 14771 | 2754 | 2136 | 0 | 27 | 0 | 14772 | 0 | 23 | 0 | 14772 | 24 | 5286 | 0 | 0 | 0 | 5305 | 46 | 101 | 2 | 0 | 0 | 6345 | 0 | 0 | 0 | 0 | 2134 | 0 | 535 | 518 | 17 | 535 | 518 | 17 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 152 | 1604 | 1528 | 0 | 0 | 1528 | 60 | 16 | 0 | 2674 |
| 10 | RESHAPE | 4 | 0 | 0 | 64 | 1*64 | 000*0 | 0 | 0 | 0 | 0 | 0 | 2 | 1 | 26 | 88 | 38 | 294 | 0 | 0 | 38 | 41 | 10 | 0 | 522 | 170 | 100 | 0 | 3 | 0 | 521 | 0 | 3 | 0 | 522 | 7 | 139 | 0 | 0 | 1 | 146 | 18 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 1 | 1 | 2 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 142 |
| 11 | FULLY_CONNECTED | 12 | 768 | 64112 | 12 | 1*12 | 12*64 | 0 | 0 | 0 | 0 | 0 | 4 | 0 | 36 | 279 | 111 | 954 | 0 | 0 | 68 | 64 | 14 | 0 | 1332 | 786 | 215 | 0 | 3 | 0 | 1332 | 0 | 3 | 0 | 1332 | 12 | 219 | 0 | 0 | 0 | 230 | 28 | 3 | 0 | 0 | 0 | 239 | 0 | 0 | 0 | 0 | 80 | 51 | 78 | 72 | 6 | 75 | 72 | 3 | 3 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 48 | 0 | 48 | 0 | 33 | 27 | 0 | 0 | 27 | 3 | 3 | 0 | 748 |
| 12 | SOFTMAX | 22 | 0 | 0 | 12 | 1*12 | 000*0 | 0 | 0 | 0 | 0 | 0 | 11 | 0 | 81 | 295 | 181 | 1781 | 0 | 0 | 58 | 66 | 14 | 0 | 2793 | 1562 | 326 | 0 | 3 | 0 | 2793 | 0 | 17 | 0 | 3324 | 29 | 954 | 0 | 0 | 0 | 990 | 84 | 0 | 0 | 0 | 0 | 995 | 0 | 0 | 0 | 0 | 698 | 87 | 240 | 122 | 118 | 240 | 122 | 118 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4 | 0 | 4 | 54 | 329 | 218 | 30 | 0 | 188 | 99 | 12 | 0 | 1480 |
Measuring Power
AutoDeploy can use a Joulescope to measure power. It does so by:
- Creating and deploying a power measurement binary to the EVB
- Triggering a number of inference operations by using the Joulescope's GP0out bin (which is monitored by the EVB)
- Waiting for certain patterns on the Joulescope's GPIn pins to know when the inference code is running
- Using Joulescope's python driver to sample power measurements during that time.
It will do this twice, once for Low Power clock mode and another for higher performance clock mode.
Requirements
- A Joulescope
- Connections between the Joulescope's GPIn and GPOut pins and the appriopriate GPIO pins (see the wiring guide below)
Connecting the Joulescope to the EVB
First, configure the power connections (follow EVB power measurement connection guide).
| Platform | Joulescope In 0 | Joulescope In 1 | Joulescope Out 0 |
|---|---|---|---|
| Apollo4 Plus | 22 | 23 | 24 |
| Apollo4 Lite | 61 | 23 | 24 |
| Apollo3 | 22 | 23 | 24 |
| Apollo5 EB | GP74 | GP75 | GP4 |
| Apollo5 EVB | 29 | 36 | 14 |
Procedure
- Plug in EVB and Joulescope
- Start the Joulescope desktop application to power on the device
- Stop the Joulescope desktop application in order to allow the Python driver to control the Joulescope instead
- Run the power measurement script
NOTE: AutoDeploy needs characterization information to create the power binary - this data can be obtained by running AutoDeploy's profiling step (it will run by default), or it can be loaded from a previous run.
Result Output
Charcterization Report for har:
[Profile] Per-Layer Statistics file: har_stats.csv
[Profile] Max Perf Inference Time (ms): 355.427
[Profile] Total Estimated MACs: 3465792
[Profile] Total CPU Cycles: 68241382
[Profile] Total Model Layers: 17
[Profile] MACs per second: 9751065.620
[Profile] Cycles per MAC: 19.690
[Power] Max Perf Inference Time (ms): 10.249
[Power] Max Perf Inference Energy (uJ): 159.257
[Power] Max Perf Inference Avg Power (mW): 9.346
[Power] Min Perf Inference Time (ms): 20.110
[Power] Min Perf Inference Energy (uJ): 190.665
[Power] Min Perf Inference Avg Power (mW): 9.481
Notes:
- Statistics marked with [Profile] are collected from the first inference, whereas [Power] statistics
are collected from the average of the 100 inferences. This will lead to slight
differences due to cache warmup, etc.
- CPU cycles are captured via Arm ETM traces
- MACs are estimated based on the number of operations in the model, not via instrumented code
Anatomy of a Model Source File
Autodeploy analyses the provided TFLite file to figure out as much as it can. It then creates and deploys a 'baseline binary' to determine some information that is only available from TFLM at runtime. At the end of this process, Autodeploy knows:
- The size of the Tensor Arena
- The size of the Resource Variable Arena
- What operations need to be declared when instantiate the model.
- The number and size of input and output tensors, and the scale and offset needed for quantizing and dequantizing those tensors.
All of this is captured in the model source file, mymodel_model.cc, which includes an init function that can be used by your application to populate the ns_model configuration struct.
kws_ap4_model.cc:
...
static constexpr int kws_ap4_ambiqsuite_tensor_arena_size = 1024 * kws_ap4_ambiqsuite_COMPUTED_ARENA_SIZE; // Computed
alignas(16) static uint8_t kws_ap4_ambiqsuite_tensor_arena[kws_ap4_ambiqsuite_tensor_arena_size]; // defaults to placing in TCM
// Resource Variable Arena
static constexpr int kws_ap4_ambiqsuite_resource_var_arena_size =
4 * (SIZE + 1) * sizeof(tflite::MicroResourceVariables); // SIZE is number of Varhandles, computed by autodeploy
alignas(16) static uint8_t kws_ap4_ambiqsuite_var_arena[kws_ap4_ambiqsuite_resource_var_arena_size];
// Further down in the code...
static tflite::MicroMutableOpResolver<6> resolver; // '6' is computed
resolver.AddConv2D(); // These layers are automatically deduced from TFLite file
resolver.AddDepthwiseConv2D();
resolver.AddAveragePool2D();
resolver.AddReshape();
resolver.AddFullyConnected();
resolver.AddSoftmax();
The initialization is available via MYMODEL_ambiqsuite_minimal_init(ns_model_state_t *ms). An example of its use and how input and output tensors can be initialized and decode is placed in the example's main() function:
kws_ap4_example.cc
...
static ns_model_state_t model;
main() {
...
int status = kws_ap4_ambiqsuite_minimal_init(&model); // model init with minimal defaults
// At this point, the model is ready to use - init and allocations were successful
// Note that the model handle is not meant to be opaque, the structure is defined
// in ns_model.h, and contains state, config details, and model structure information
// Get data about input and output tensors
int numInputs = model.numInputTensors;
int numOutputs = model.numOutputTensors;
// Initialize input tensors
int offset = 0;
for (int i = 0; i < numInputs; i++) {
am_util_debug_printf("Initializing input tensor %d (%d bytes)\n", i, model.model_input[i]->bytes);
memcpy(model.model_input[i]->data.int8, ((char *)kws_ap4_ambiqsuite_example_input_tensors) + offset,
model.model_input[i]->bytes);
offset += model.model_input[i]->bytes;
}
// Execute the model
am_util_stdio_printf("Invoking model...");
TfLiteStatus invoke_status = model.interpreter->Invoke();
am_util_stdio_printf(" success!\n");
if (invoke_status != kTfLiteOk) {
while (1)
example_status = kws_ap4_ambiqsuite_STATUS_FAILURE; // invoke failed, so hang
}
// Compare the bytes of the output tensors against expected values
offset = 0;
am_util_stdio_printf("Checking %d output tensors\n", numOutputs);
for (int i = 0; i < numOutputs; i++) {
am_util_stdio_printf("Checking output tensor %d (%d bytes)\n", i, model.model_output[i]->bytes);
if (0 != memcmp(model.model_output[i]->data.int8,
((char *)kws_ap4_ambiqsuite_example_output_tensors) + offset,
model.model_output[i]->bytes)) {
// Miscompare!
am_util_stdio_printf("Miscompare in output tensor %d\n", i);
while (1)
example_status = kws_ap4_ambiqsuite_STATUS_INVALID_CONFIG; // miscompare, so hang
}
offset += model.model_output[i]->bytes;
}
am_util_stdio_printf("All output tensors matched expected results.\n");
...
}